




声明:本文章所述内容仅用于个人开发学习,不含任何商业目的,侵权联系作者删除。
引言
前段时间想再开发一款小程序供自己使用,但还没有具体方案和灵感,后来无意中被自己菜鸡的英文水准给刺激了,决定开发一款用于英语学习的小程序。
目前正在开发这款用于英语阅读学习的微信小程序,没有什么好名字,就打算叫它“米瑶英语阅读”。
开始编写日期是前天晚上。前天晚上完成了小程序的文章解析、单词翻译功能。昨天上午完成了文章翻译功能。
主要原理是运用已经存在的api接口,然后对内容进行初步处理然后进行网络请求。基于小程序的特有性质,部分请求用到了小程序的云开发功能。
昨天晚上开始对四六级文章进行爬取,并上传文章至数据库保存起来。本文章的内容主要是整理一下昨天晚上爬虫的成果。
工具
-
爬取的网站:沪江英语网站
-
爬虫所用的语言:JavaScript
-
爬虫的平台:微信开发者工具
分析
也许目前主要流行的爬虫都是基于python的,但实际上JavaScript的特性决定了它实际上更适合作为爬虫所用的计算机语言:
JavaScript异步IO机制适用于爬虫这种IO密集型任务。JavaScript中的回调非常自然,使用异步网络请求能够充分利用CPU。JavaScript中的jQuery毫无疑问是最强悍的HTML解析工具,使用JavaScript写爬虫能够减少学习负担和记忆负担。虽然Python中有PyQuery,但终究还是比不上jQuery自然。- 爬取结果多为
JSON,JavaScript是最适合处理JSON的语言。
过程
环境
由于是基于小程序开发的,因此本此爬虫用的环境就是小程序开发的环境,没有特殊要求。实际上本次实验不需要什么特殊环境,记事本都可以开发。
原理
爬虫的原理也不算复杂,网络爬虫就是自动抓取网页信息的代码,可以简单理解成代替繁琐的复制粘贴操作的手段。
要求
-
明确自己要爬取的目标网站,目标网站必须是具体的,而不是抽象的、不确定的。
-
其次,还要知道需要获取的内容是什么,如果没有目标,爬虫是无意义的。
操作
现在就可以开始操作啦~
-
首先,找到目标网站网址:
这里,以沪江英语2020年9月四级真题:
-
编写请求代码:
//getArticle.js:
const article = (url) => {
return new Promise((resolve, reject) => {
wx.request({
url: url,
success: (res) => {
resolve(res)
},
fail: (err) => {
reject(err)
}
})
})
}
module.exports={
article
}
javascript解释:其中,第三行表示定义一个常函数
article,需要传入的参数是url,即网址。返回一个promise请求,即,调用的时候可以用.then()获取成功的返回结果并处理,用.catch()获取失败的返回结果并处理。第五行是微信内置函数:wx.request(),参数为url和data,格式如下:
wx.request({
url: url,
data:{
},
success: (res) => {
console.log(res)
},
fail: (err) => {
console.log(err)
}
})
javascript当然,
data不是必要参数,可以用ES6字符串的拼接方法传入url也行。针对复杂的请求,还需要传入header等参数,读者自行研究。
第8行返回成功结果,第10行返回失败结果。第16行
module.exports={}
的作用是将本函数暴露出接口,供其他包里的js文件调用。
- 编写调用代码:
const { article } = require("../../utils/getArticle.js")
//获取网页里的文章 信息
getWebPage() {
var result = []
article("https://www.hjenglish.com/sijidaan/p1316887/")
.then(res => {
var arr = this.getLinkUrl(res.data)
arr.forEach((item, index) => {
getArticle(item)
})
})
.catch(err => {
console.log(err)
})
},
//获取文章
getArticle(item){
if (item.substr(0, 4) == 'http') {
artic(item)
.then(res => {
console.log(res)
var a = res.data
a = a.replace(/style="(.*?)"/gi, "")
result.push({
content: this.getP(a),
title: this.getTitle(a),
url: item
})
console.log(result)
this.setData({result: result})
})
.catch(err => {
console.log(err)
})
}
},
//获取<a>标签的内容
getLinkUrl(str) {
var a = str;
var arrLink = [];
a.replace(/<a [^>]*href=['"]([^'"]+)[^>]*/gi,
function (match, capture) {
arrLink.push(capture)
});
if (arrLink != null && arrLink.length > 0) {
return arrLink;
}
},
//获取<p>标签的内容
getP(str) {
var a = str;
var arrLink = [];
a.replace(/<p>(.*?)<\/p>/gi,
function (match, capture) {
arrLink.push(capture)
});
if (arrLink != null && arrLink.length > 0) {
return arrLink;
} else {
return this.getP(str)
}
},
//获取文章标题
getTitle(str) {
var a = str;
var title = '';
a.replace(/<title>(.*?)<\/title>/,
function (match, capture) {
title = capture
})
if (title != "") {
return title;
}
}
javascript解释:代码第一行是导入
article函数。
上文提到了四个函数:
getWebPage() getArticle() getLinkUrl(str) getP(str) getTitle(str)
函数getWebPage() 是获取网页信息的函数,
函数getArticle() 是获取文章信息的函数,
函数getLinkUrl(str) 是获取文章链接的函数,
函数getP(str) 是获取文章内容的函数,
函数getTitle(str) 是获取文章标题的函数
获取文章链接、文章内容、文章标题军事通过运用正则表达式来处理request请求返回的结果得到的
执行顺序
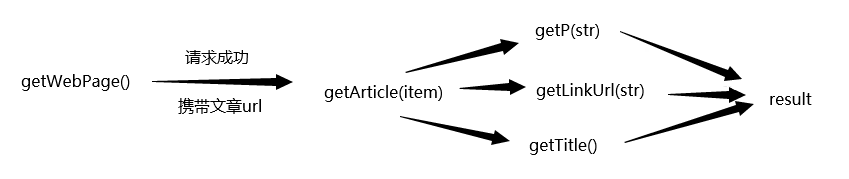
其中:
//表示匹配所有的<p></p>标签的内容
/<p>(.*?)<\/p>/gi
javascript//匹配<title></title>标签
/<title>(.*?)<\/title>/
javascript//匹配所有<a></a>标签的href链接
/<a [^>]*href=['"]([^'"]+)[^>]*/gi
javascript然后逐一请求返回结果就行了。
- 分析过程:
首先,目标网页在浏览器里看到的是这样的▼
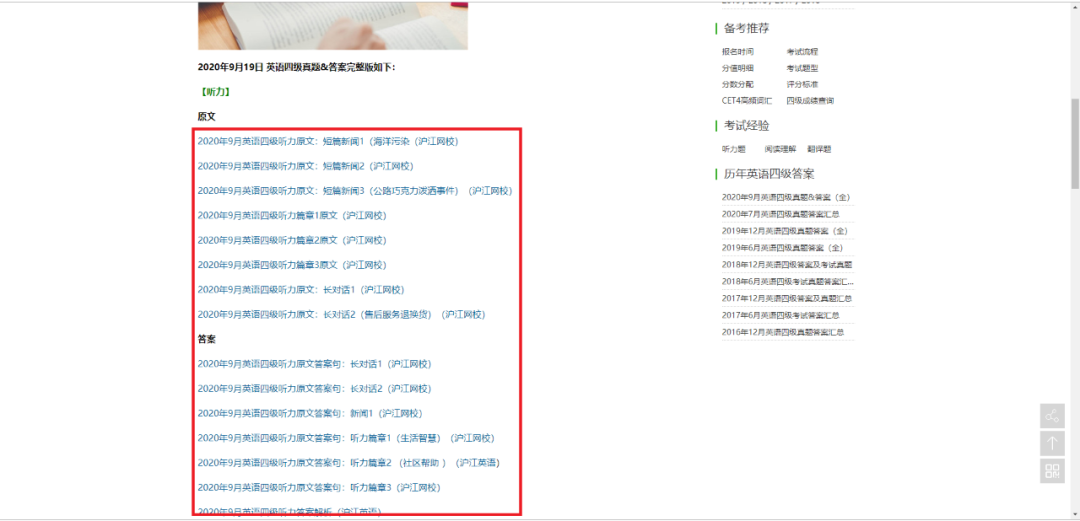
找到我们需要的部分▼
通过检查元素▼
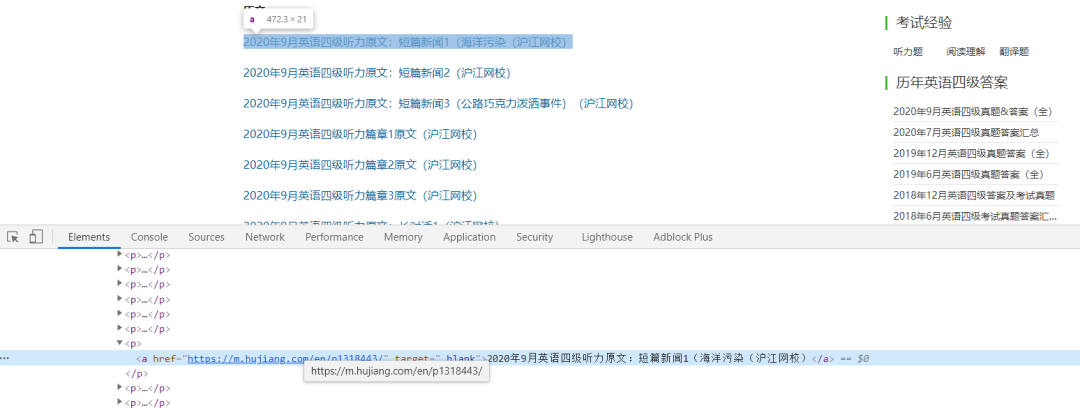
可以判断,我们首先需要的就是<a>标签里面的href链接,这个链接就是文章的链接
查看网页源代码▼
找到我们需要的部分▼

可以看到,只要把所有的<a>标签获取下来,然后遍历请求就可以获得当前网页下的所有文章了。
-
执行:
-
运行getWebPage(),查看log输出:
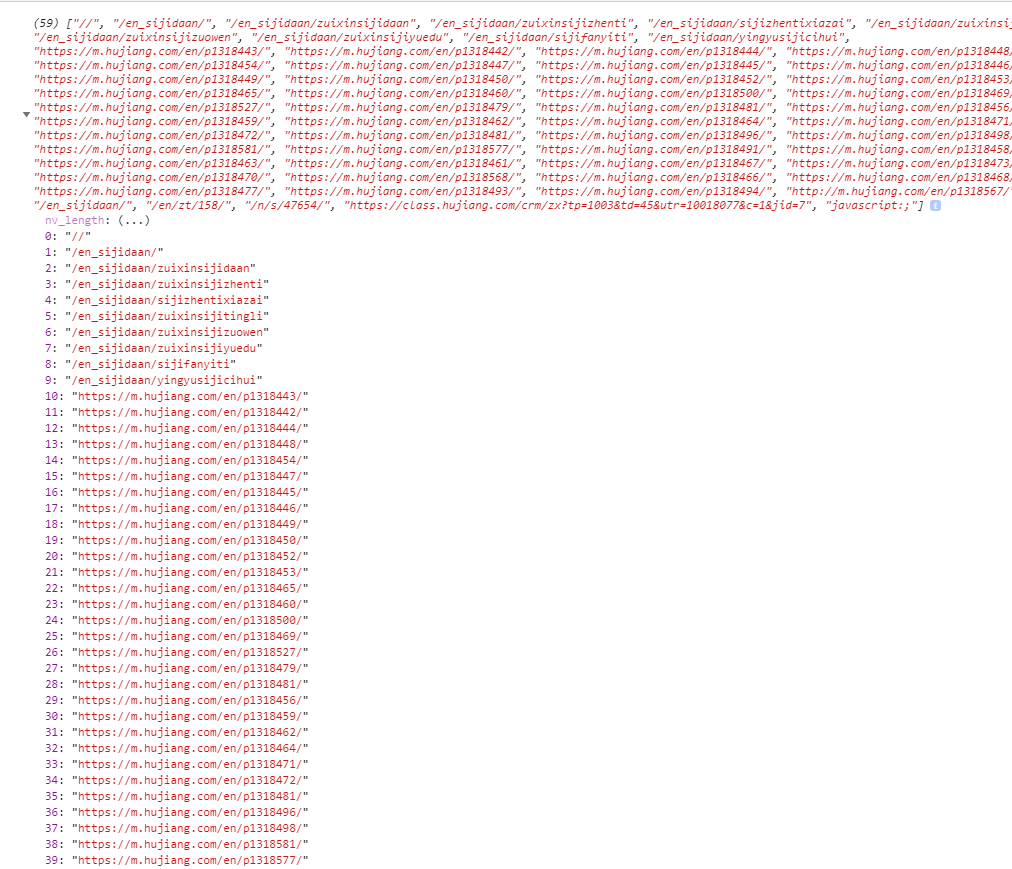
说明获取文章链接成功了,这里拿到了59条数据,但是很显然发现有很多是无效的信息,比如前11条数据均无效,因此在遍历的时候,需要做一个判断,判断的方法很简单,只需要判断四负川的前四位是否是http即可。
然后遍历数组,执行getArticle(item)函数,查看log
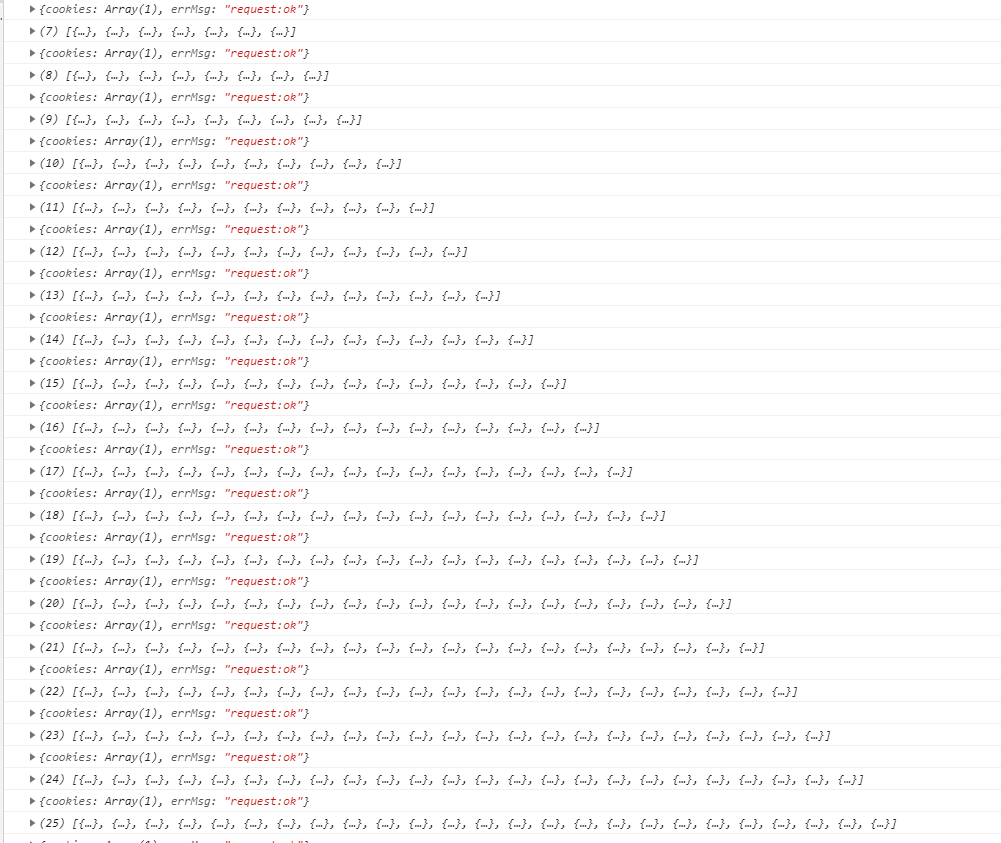
这便是获取到的文章数组信息,展开其中一个

这就是文章的详细信息,进一步展开:

到这里,已经完成了四级文章的爬取工作
- 通过小程序显示
得到如下效果:


总结
本次爬虫过程比较简单,没有涉及到加密、解析等过程,适合新手学习。通过完整的梳理和复盘,可以看到主要的部分在于找到需要的内容,并截取下来,这里主要运用的是正则表达式的方法,结合字符串操作,如:
getLinkUrl(str) {
var a = str;
var arrLink = [];
a.replace(/<a [^>]*href=['"]([^'"]+)[^>]*/gi,
function (match, capture) {
arrLink.push(capture)
});
if (arrLink != null && arrLink.length > 0) {
return arrLink;
}
}
javascript上述代码第4行便是利用正则表达式匹配所有的<a>标签拿到href的链接内容。函数很简单,只需要稍微掌握一下正则表达式即可领会。
获取文章正文是利用匹配<p>标签得到的,但是很可能会存在<p>标签里面有其他属性,如class、style等,这时,就需要先对字符串进行去除class、style等属性的操作,其实步骤都是一样的,还是通过正则表达式和replace方法实现。除此之外,有的文章不是写在<p>标签里面的,而是写在
以上就是本文的全部内容,非专业技术型人员,纯属外行自娱自乐罢,不喜勿喷,嘿嘿
最后,感谢沪江英语






